
Introduction
As a data scientist with over a decade of experience, I’ve witnessed firsthand how choosing the right algorithm can make or break your machine learning project. Moreover, the debate between Random Forests and Gradient Boosting continues to challenge even seasoned professionals. After all, both are ensemble methods that leverage decision trees, yet they operate on fundamentally different principles.
In this comprehensive guide, therefore, I’ll walk you through when to deploy each method, specifically exploring their strengths, weaknesses, and ideal use cases. Additionally, I’ll provide practical implementation examples to help you apply these powerful algorithms effectively in your projects. Consequently, by the end of this post, you’ll have a clear roadmap for navigating these popular techniques.
Understanding the Fundamentals of Random FOrest & Gradient Boosting
What Are Random Forests?
Random Forests, first proposed by Leo Breiman in 2001, operate on a simple yet powerful principle: the wisdom of crowds. In essence, they create multiple decision trees and merge them together to get a more accurate and stable prediction. Furthermore, they introduce two key concepts to ensure diversity among the trees:
- Bootstrap Aggregating (Bagging): Meanwhile, each tree is trained on a random sample of the training data with replacement.
- Feature Randomness: Subsequently, each node in a tree considers only a random subset of features when determining the best split.
As a result, Random Forests reduce overfitting compared to individual decision trees and generally produce more reliable predictions.
What Is Gradient Boosting?
Gradient Boosting, on the other hand, takes a sequential approach. Initially, it starts with a simple model (usually a shallow decision tree). Subsequently, it builds new models that focus on the errors of previous models. In other words, each new tree tries to correct the mistakes made by the ensemble of existing trees.
The “gradient” in Gradient Boosting comes from the use of gradient descent to minimize errors. Undoubtedly, this sequential learning process makes it particularly powerful for complex relationships in data. Nevertheless, it also makes it more prone to overfitting if not carefully tuned.
Key Differences: Random Forests vs. Gradient Boosting
Building Strategy
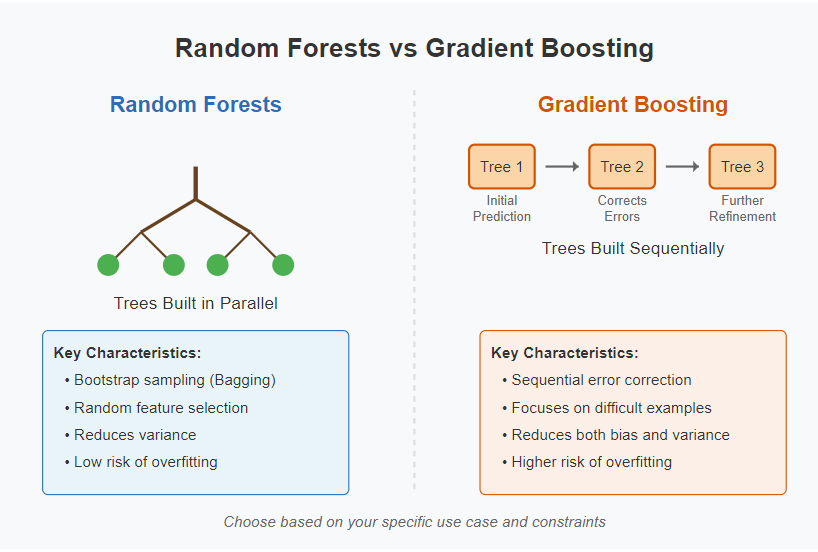
Random Forests build trees in parallel, whereas Gradient Boosting builds them sequentially. Consequently, this fundamental difference influences their performance characteristics, training speed, and hyperparameter sensitivity.
Error Handling
Random Forests reduce errors primarily through averaging, thereby reducing variance. In contrast, Gradient Boosting directly addresses errors from previous models, thus reducing both bias and variance but with greater risk of overfitting.
Training Speed
Due to their parallel nature, Random Forests often train faster and are easier to parallelize across multiple cores or machines. Meanwhile, Gradient Boosting’s sequential nature makes it inherently slower and harder to parallelize.
Hyperparameter Sensitivity
Random Forests are relatively robust to hyperparameter settings; hence, they often work well with default parameters. Alternatively, Gradient Boosting algorithms typically require careful tuning to achieve optimal performance.
When to Use Random Forests
Random Forests shine in several scenarios:
- When you need robustness: Above all, Random Forests are less prone to overfitting, especially with high-dimensional data.
- When interpretability matters: Although ensemble methods are generally less interpretable than single decision trees, Random Forests offer feature importance measures that are often more reliable than those from Gradient Boosting.
- When training speed is a concern: Furthermore, their parallel nature makes them faster to train on large datasets.
- When handling missing values: Notably, Random Forests can handle missing values effectively through their bootstrap sampling.
- When you have limited time for hyperparameter tuning: Because they’re less sensitive to parameter settings, you can often get good results with minimal tuning.
Let’s implement a simple Random Forest classifier using scikit-learn:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
# Load sample dataset (using iris for this example)
from sklearn.datasets import load_iris
data = load_iris()
X, y = data.data, data.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train a Random Forest with default parameters
rf_default = RandomForestClassifier(random_state=42)
rf_default.fit(X_train, y_train)
# Make predictions
y_pred = rf_default.predict(X_test)
print(f"Default Random Forest Accuracy: {accuracy_score(y_test, y_pred):.4f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
# Feature importance visualization
feature_importance = pd.DataFrame(
{'feature': data.feature_names,
'importance': rf_default.feature_importances_}
).sort_values('importance', ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(x='importance', y='feature', data=feature_importance)
plt.title('Random Forest Feature Importance')
plt.tight_layout()
plt.show()
# Grid search for hyperparameter tuning (if needed)
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# Uncomment for hyperparameter tuning
# grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, scoring='accuracy')
# grid_search.fit(X_train, y_train)
# print(f"Best parameters: {grid_search.best_params_}")
# best_rf = grid_search.best_estimator_When to Use Gradient Boosting
Gradient Boosting excels in these scenarios:
- When you need maximum predictive performance: Undoubtedly, Gradient Boosting often achieves state-of-the-art results in structured data competitions.
- When dealing with complex relationships: Similarly, its sequential nature helps it capture intricate patterns that Random Forests might miss.
- When you have sufficient time for hyperparameter tuning: Obviously, the performance gains often require careful optimization.
- For regression tasks: In particular, Gradient Boosting frequently outperforms Random Forests on regression problems.
- When you have moderately-sized datasets: Although it can handle large data, it particularly shines on medium-sized datasets where its computational complexity is manageable.
Here’s an implementation example using XGBoost, a popular Gradient Boosting framework:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import xgboost as xgb
from sklearn.datasets import load_iris
# Load dataset
data = load_iris()
X, y = data.data, data.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train XGBoost with default parameters
xgb_default = xgb.XGBClassifier(random_state=42)
xgb_default.fit(X_train, y_train)
# Make predictions
y_pred = xgb_default.predict(X_test)
print(f"Default XGBoost Accuracy: {accuracy_score(y_test, y_pred):.4f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
# Feature importance visualization
feature_importance = pd.DataFrame(
{'feature': data.feature_names,
'importance': xgb_default.feature_importances_}
).sort_values('importance', ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(x='importance', y='feature', data=feature_importance)
plt.title('XGBoost Feature Importance')
plt.tight_layout()
plt.show()
# Hyperparameter tuning example
param_grid = {
'learning_rate': [0.01, 0.1, 0.3],
'max_depth': [3, 5, 7, 9],
'n_estimators': [50, 100, 200],
'subsample': [0.8, 1.0],
'colsample_bytree': [0.8, 1.0]
}
# Uncomment for hyperparameter tuning
# grid_search = GridSearchCV(xgb.XGBClassifier(random_state=42), param_grid, cv=5, scoring='accuracy')
# grid_search.fit(X_train, y_train)
# print(f"Best parameters: {grid_search.best_params_}")
# best_xgb = grid_search.best_estimator_
# Learning curves visualization
def plot_learning_curves(model, X_train, y_train, X_test, y_test):
train_scores = []
test_scores = []
estimator_range = range(10, 210, 10)
for n_estimators in estimator_range:
model.n_estimators = n_estimators
model.fit(X_train, y_train)
train_pred = model.predict(X_train)
test_pred = model.predict(X_test)
train_scores.append(accuracy_score(y_train, train_pred))
test_scores.append(accuracy_score(y_test, test_pred))
plt.figure(figsize=(10, 6))
plt.plot(estimator_range, train_scores, 'o-', color='blue', label='Training accuracy')
plt.plot(estimator_range, test_scores, 'o-', color='red', label='Testing accuracy')
plt.xlabel('Number of Estimators')
plt.ylabel('Accuracy')
plt.title('XGBoost Learning Curves')
plt.legend()
plt.grid(True)
plt.show()
# Uncomment to visualize learning curves
# plot_learning_curves(xgb.XGBClassifier(random_state=42), X_train, y_train, X_test, y_test)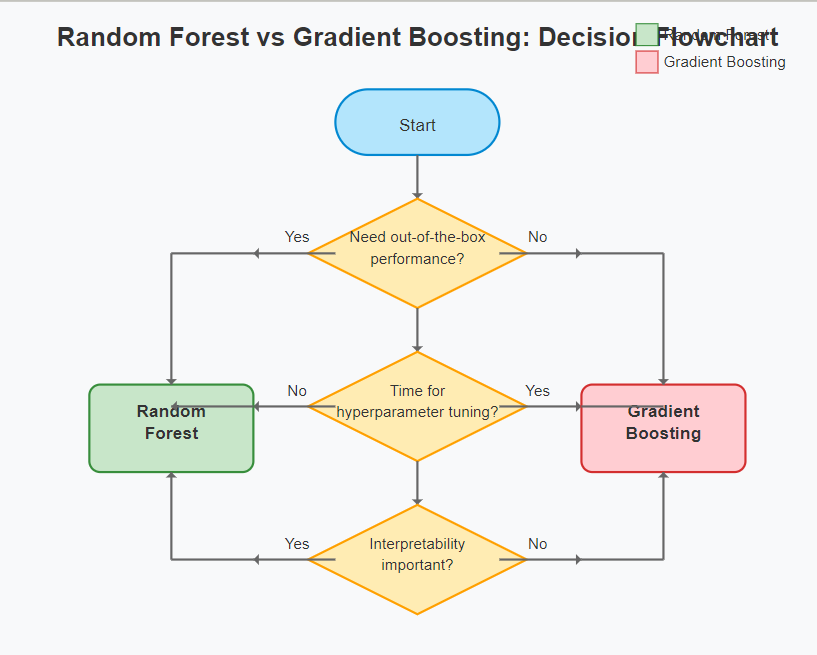
Real-World Case Studies of Random Forest & Gradient Boosting
Case Study 1: Credit Risk Assessment
In a credit risk prediction project I worked on, Random Forests proved more effective. Surprisingly, the data had numerous categorical features with missing values, and the client needed explanations for credit decisions. Therefore, Random Forests provided both good accuracy and more interpretable feature importance values that satisfied regulatory requirements.
Case Study 2: Click-Through Rate Prediction
Conversely, for an advertising platform’s click prediction model, Gradient Boosting (specifically LightGBM) outperformed other algorithms. In addition, the sequential learning approach captured subtle interaction patterns between features that drove user engagement. Furthermore, after careful hyperparameter tuning, the model improved click-through rates by 23% compared to the previous system.
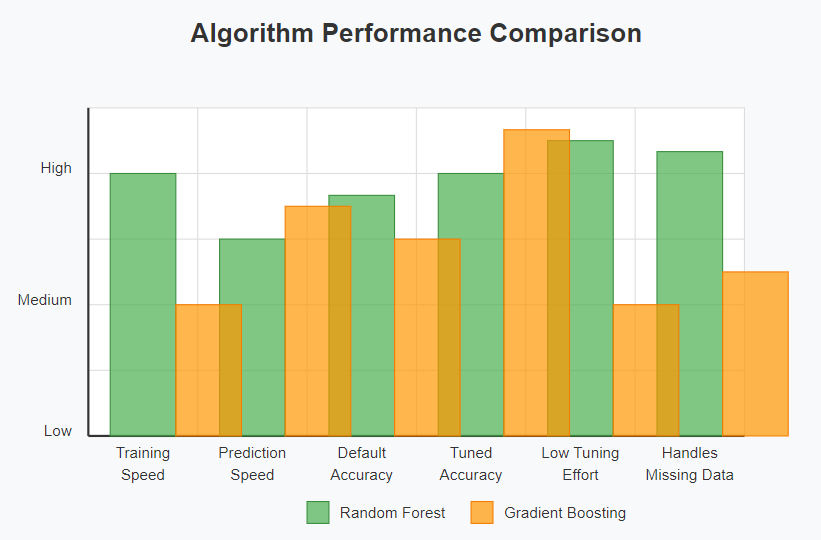
Performance Comparison
Let’s compare the typical performance characteristics:
| Aspect | Random Forests | Gradient Boosting |
| Training Speed | Faster (parallel) | Slower (sequential) |
| Prediction Speed | Moderate | Fast (with shallow trees) |
| Accuracy (default settings) | Good | Moderate |
| Accuracy (tuned) | Very Good | Excellent |
| Overfitting Risk | Lower | Higher |
| Hyperparameter Sensitivity | Low | High |
| Memory Usage | Higher | Lower |
Implementation Considerations of Random Forest and gradient Boosting
Hyperparameter Tuning Tips
For Random Forests, focus on:
n_estimators: Usually, more trees improve performance up to a point.max_features: Controls feature randomness; common values are ‘sqrt’ or ‘log2’.max_depth: Limits tree depth to control overfitting.
For Gradient Boosting, prioritize:
learning_rate: Lower values (0.01-0.1) usually work better but require more trees.n_estimators: Increase this as you decrease learning rate.max_depth: Often shallower trees (3-5) work best.subsample: Using values < 1.0 helps prevent overfitting.
Popular Implementations
Several excellent implementations are available:
- Random Forests:
- Scikit-learn’s RandomForestClassifier/RandomForestRegressor
- H2O’s RandomForest
- Gradient Boosting:
- XGBoost
- LightGBM
- CatBoost
- Scikit-learn’s GradientBoostingClassifier/GradientBoostingRegressor
Best Practices for Random Forest and Gradient Boosting Algorithms
Regardless of which algorithm you choose, consider these best practices:
- Start simple: Begin with default parameters before diving into complex tuning.
- Cross-validation: Always use cross-validation to ensure your model generalizes well.
- Feature engineering: Both algorithms benefit from thoughtful feature engineering, although Gradient Boosting may extract more value from raw features.
- Class imbalance: For imbalanced classifications, both algorithms support class weighting or sampling techniques.
- Ensemble the ensembles: Sometimes, the best approach is to ensemble predictions from both algorithms!
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.metrics import accuracy_score, classification_report
import xgboost as xgb
from sklearn.datasets import load_iris
# Load dataset
data = load_iris()
X, y = data.data, data.target
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create base models
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
xgb_model = xgb.XGBClassifier(n_estimators=100, random_state=42)
# Train individual models
rf_model.fit(X_train, y_train)
xgb_model.fit(X_train, y_train)
# Make individual predictions
rf_pred = rf_model.predict(X_test)
xgb_pred = xgb_model.predict(X_test)
print(f"Random Forest Accuracy: {accuracy_score(y_test, rf_pred):.4f}")
print(f"XGBoost Accuracy: {accuracy_score(y_test, xgb_pred):.4f}")
# Create ensemble using VotingClassifier
ensemble = VotingClassifier(
estimators=[
('rf', rf_model),
('xgb', xgb_model)
],
voting='soft' # Use probability estimates for voting
)
# Train ensemble
ensemble.fit(X_train, y_train)
ensemble_pred = ensemble.predict(X_test)
print(f"Ensemble Accuracy: {accuracy_score(y_test, ensemble_pred):.4f}")
print("\nEnsemble Classification Report:")
print(classification_report(y_test, ensemble_pred))
# Weighted ensemble approach (alternative method)
def weighted_ensemble_prediction(rf_probs, xgb_probs, rf_weight=0.4, xgb_weight=0.6):
"""Combine predictions with custom weights"""
weighted_probs = (rf_weight * rf_probs) + (xgb_weight * xgb_probs)
return np.argmax(weighted_probs, axis=1)
# Get probability predictions
rf_probs = rf_model.predict_proba(X_test)
xgb_probs = xgb_model.predict_proba(X_test)
# Create weighted ensemble prediction
weighted_pred = weighted_ensemble_prediction(rf_probs, xgb_probs)
print(f"Weighted Ensemble Accuracy: {accuracy_score(y_test, weighted_pred):.4f}")Practical Decision Framework
To simplify your algorithm selection, follow this decision framework:
- Start with Random Forests if:
- You need good out-of-the-box performance
- Interpretability is important
- You have limited time for tuning
- Your data has many categorical features and missing values
- Choose Gradient Boosting if:
- Maximum predictive performance is critical
- You can invest time in hyperparameter tuning
- You’re working on a regression problem
- Computing resources aren’t a major constraint
- Try both and ensemble them when:
- You have the computational resources
- The stakes are high (e.g., medical diagnosis, financial predictions)
- Even small improvements in accuracy matter
Conclusion
While both Random Forests and Gradient Boosting are powerful ensemble methods, they serve different needs and scenarios. Indeed, Random Forests offer robustness, ease of use, and good interpretability with minimal tuning. Conversely, Gradient Boosting provides superior predictive performance when properly optimized.
In my experience, the best approach is often pragmatic: start with Random Forests to establish a solid baseline, then explore if Gradient Boosting can deliver meaningful improvements given your specific constraints and requirements. Additionally, don’t forget that ensemble methods shine brightest when you combine their strengths!
Finally, remember that no algorithm exists in isolation—your domain knowledge, feature engineering, and proper validation practices will ultimately have the greatest impact on your model’s success.
References
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.
- Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. KDD ’16.
- Prokhorenkova, L., et al. (2018). CatBoost: unbiased boosting with categorical features. NeurIPS.
- Scikit-learn documentation: Ensemble methods.
- Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29(5), 1189-1232.
- Unsupervised Learning When AI Discovers Hidden Patterns on its own
- The Ultimate Guide to Model Evaluation: Accuracy, Precision, Recall & F1-Score