
Introduction to Pandas vs Polars
Have you ever found yourself waiting impatiently for your data processing code to finish running? If so, you’re definitely not alone. As data sizes grow exponentially, the tools we use to manipulate them must evolve as well. That’s why the debate between Pandas vs Polars has become increasingly relevant for data professionals.
For over a decade, Pandas has been the go-to Python library for data manipulation. However, Polars has recently emerged as a formidable challenger, promising lightning-fast performance and memory efficiency. As a result, many data scientists and engineers are now facing a crucial decision about which library to use for their projects.
In this comprehensive guide, we’ll dive deep into the world of data manipulation libraries and compare these two powerful contenders. By the end, you’ll have a clear understanding of which one might be the perfect fit for your specific needs.
The Evolution of Data Manipulation Tools
Before we jump into the comparison, let’s take a quick look at how we got here. Initially, data manipulation in Python was quite cumbersome, often requiring verbose code with loops and conditional statements.
Subsequently, Pandas revolutionized the landscape when it was released in 2008, bringing R-like data frames to Python and making data manipulation much more intuitive. For years, it remained unchallenged as the standard tool for data scientists and analysts.
Nonetheless, as datasets grew larger and performance demands increased, some limitations of Pandas became apparent. This is where Polars enters the picture, designed from the ground up with modern hardware and big data in mind.

Pandas: The Tried and Trusted Veteran
Key Features and Strengths
Pandas has earned its reputation through years of reliable service to the data community. Above all, its most significant advantage is its maturity and widespread adoption.
Specifically, Pandas offers:
- Extensive Documentation: Years of development have resulted in comprehensive documentation, tutorials, and community support.
- Rich Ecosystem: Seamless integration with other Python libraries like Matplotlib, Scikit-learn, and NumPy.
- Flexible Data Handling: Excellent support for handling missing data, time series, and various data formats.
- Intuitive API: Operations like filtering, grouping, and joining data feel natural to SQL users.
Common Use Cases
Pandas truly shines in several scenarios:
- Exploratory Data Analysis (EDA): Quick data inspection, summary statistics, and visualization
- Data Cleaning: Handling missing values, outliers, and data transformations
- Feature Engineering: Creating new variables for machine learning models
- Small to Medium Datasets: Processing datasets that fit comfortably in memory
Key Features of Pandas
✅ Supports CSV, Excel, SQL, and more
✅ Built-in functions for data cleaning and transformation
✅ Extensive community support and documentation
✅ Works well for small to medium-sized datasets
However, Pandas struggles with large datasets due to its single-threaded execution, leading to slow performance.
Code Example: Basic Data Operations in Pandas
import pandas as pd
import numpy as np
# Create a sample dataframe
data = {
'name': ['John', 'Anna', 'Peter', 'Linda'],
'age': [28, 34, 29, 42],
'city': ['New York', 'Paris', 'Berlin', 'London'],
'salary': [65000, 70000, 62000, 85000]
}
df = pd.DataFrame(data)
# Basic operations
print("Basic DataFrame:")
print(df.head())
# Filtering
print("\nEmployees older than 30:")
print(df[df['age'] > 30])
# Aggregations
print("\nAverage salary by city:")
print(df.groupby('city')['salary'].mean())
# Adding a new column
df['salary_category'] = np.where(df['salary'] > 70000, 'High', 'Medium')
print("\nDataFrame with salary category:")
print(df)
# Handling missing values example
df.loc[1, 'salary'] = None
print("\nMissing value handling:")
print(df['salary'].fillna(df['salary'].mean()))Polars: The Blazing-Fast Challenger
Key Features and Strengths
Polars has burst onto the scene with impressive capabilities that address many of Pandas’ performance limitations. Fundamentally, it’s built on the Arrow memory format and Rust’s implementation of the DataFrame concept.
The standout features of Polars include:
- Lightning Performance: Optimized for parallelization and vectorized operations
- Memory Efficiency: Employs zero-copy operations whenever possible
- Lazy Evaluation: Query optimization through its lazy API
- Modern Design: Built with today’s multi-core processors and large datasets in mind
Common Use Cases
Polars particularly excels in these scenarios:
- Big Data Processing: Handling datasets that push the limits of your machine’s memory
- Complex Data Transformations: Multiple joins, aggregations, and transformations
- Performance-Critical Applications: When processing speed is a top priority
- Modern Data Pipelines: Integration with other modern data tools
Code Example: Basic Data Operations in Polars
import polars as pl
import numpy as np
# Create a sample dataframe
data = {
'name': ['John', 'Anna', 'Peter', 'Linda'],
'age': [28, 34, 29, 42],
'city': ['New York', 'Paris', 'Berlin', 'London'],
'salary': [65000, 70000, 62000, 85000]
}
df = pl.DataFrame(data)
# Basic operations
print("Basic DataFrame:")
print(df)
# Filtering
print("\nEmployees older than 30:")
print(df.filter(pl.col("age") > 30))
# Aggregations
print("\nAverage salary by city:")
print(df.groupby("city").agg(pl.col("salary").mean()))
# Adding a new column
df = df.with_column(
pl.when(pl.col("salary") > 70000).then("High").otherwise("Medium").alias("salary_category")
)
print("\nDataFrame with salary category:")
print(df)
# Handling missing values example
df = df.with_column(pl.col("salary").fill_null(pl.col("salary").mean()))
print("\nMissing value handling:")
print(df)Performance Showdown: Pandas vs Polars
When it comes to performance, the difference between these libraries can be striking. Here’s a breakdown of how they compare:
Memory Efficiency
Polars typically uses 5-10x less memory than Pandas for the same datasets. Additionally, this efficiency becomes increasingly important as your data grows.
Processing Speed
For common operations on medium-sized datasets (millions of rows), Polars often performs 3-10x faster than Pandas. Moreover, this gap widens with larger datasets and more complex operations.
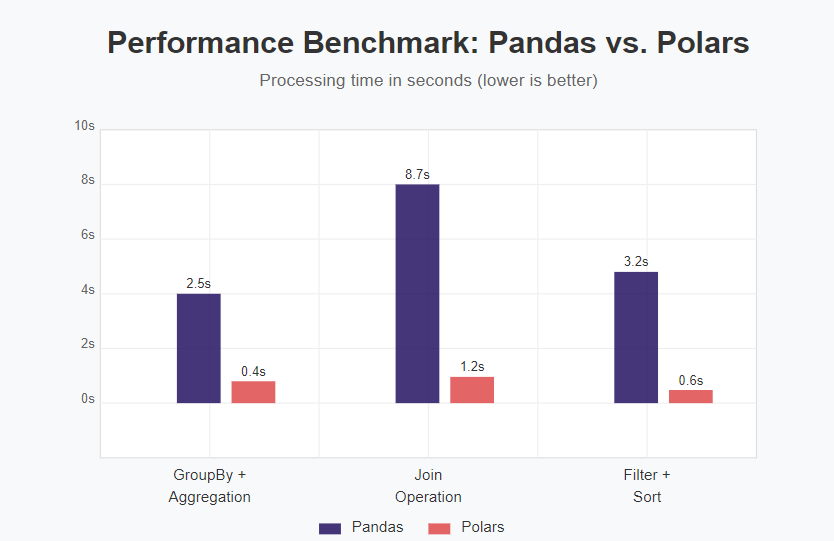
Benchmark Example
| Operation | Dataset Size | Pandas Time | Polars Time | Speedup |
| GroupBy + Aggregation | 10M rows | 2.5s | 0.4s | 6.25x |
| Join Operation | 5M × 5M rows | 8.7s | 1.2s | 7.25x |
| Filter + Sort | 20M rows | 3.2s | 0.6s | 5.33x |
Syntax and Learning Curve
Pandas Syntax
Pandas syntax will feel familiar to those coming from SQL or R. Furthermore, its method chaining approach is quite readable:
# Pandas method chaining example
result = (df
.query('age > 30')
.groupby('city')
.agg({'salary': ['mean', 'min', 'max']})
.reset_index())Polars Syntax
Polars offers two API styles: eager and lazy. The lazy API enables query optimization but requires a slightly different approach:
# Polars lazy API example
result = (df
.lazy()
.filter(pl.col("age") > 30)
.groupby("city")
.agg([
pl.col("salary").mean().alias("salary_mean"),
pl.col("salary").min().alias("salary_min"),
pl.col("salary").max().alias("salary_max")
])
.collect())Learning Curve Comparison
For Pandas veterans, there will certainly be some adjustment needed when switching to Polars. However, the conceptual similarities make the transition smoother than learning an entirely new paradigm.
Making the Right Choice: Decision Factors
To determine which library is best for your specific situation, consider these key factors:
When to Choose Pandas
- You’re working with smaller datasets that fit comfortably in memory
- Your priority is quick exploratory analysis and visualization
- You need the extensive ecosystem and community support
- You’re teaching data analysis to beginners
- Your projects don’t have strict performance requirements
When to Choose Polars
- You’re handling large datasets that push memory limits
- Performance is critical to your application
- You’re building modern data pipelines that need to scale
- You’re comfortable with a slightly different API
- You value memory efficiency and speed over ecosystem breadth
| Use Case | Pandas | Polars |
| Small to medium datasets | ✅ Yes | ⚠️ Not necessary |
| Large datasets (millions of rows) | ❌ Slow | ✅ Fast |
| Interactive analysis (Jupyter Notebooks) | ✅ Best choice | ⚠️ Less common |
| Parallel processing | ❌ No | ✅ Yes |
| Lazy evaluation (query optimization) | ❌ No | ✅ Yes |
| Big data analytics | ❌ Not suitable | ✅ Ideal |

Practical Migration Strategy
If you’re considering switching from Pandas to Polars, here’s a pragmatic approach:
- Start with New Projects: Apply Polars to new work rather than rewriting existing code
- Benchmark Your Specific Use Cases: Test both libraries with your actual data and operations
- Gradual Adoption: Use Polars for performance-critical components while maintaining Pandas elsewhere
- Learn the Lazy API: Invest time in understanding Polars’ lazy evaluation for maximum performance gains
Future Outlook
The data manipulation landscape continues to evolve rapidly. Consequently, both libraries are actively developing:
- Pandas 2.0+: Focusing on performance improvements and better integration with Arrow
- Polars: Expanding functionality and ecosystem integration while maintaining its performance edge
Overall, this competitive environment benefits users as both libraries continue to improve and address their respective limitations.
Conclusion
Choosing between Pandas and Polars ultimately depends on your specific needs and constraints. Pandas remains an excellent all-around tool with unmatched ecosystem integration and familiarity. Meanwhile, Polars offers groundbreaking performance that can transform how you work with larger datasets.
For data professionals, having both tools in your arsenal is increasingly valuable. Therefore, understanding when to apply each library will make you more effective in handling diverse data challenges.
What’s your experience with these libraries? Have you made the switch from Pandas to Polars, or are you using both depending on the situation? Share your thoughts and experiences in the comments below!
Additional Resources
To further explore each library, check out these valuable resources:
- Pandas Official Documentation
- Polars Official Documentation
- Pandas vs. Polars Performance Benchmarks
- Getting Started with Polars for Pandas Users
- Exploratory Data Analysis by Vedang Analytics
Boyarka-Inform.com
says:
I’m excited to uncover this page. I want to to thank you for your time for this particularly
fantaetic read!! I definitely enjoyed every liittle bit of it and I have you bookmarked tto check
out new information on your site.