Action Recognition in Videos with Computer Vision: A Deep Dive into AI-Powered Video Analysis
Introduction
In an era where video content dominates the internet, Action Recognition in Videos with Computer Vision is transforming industries like security, healthcare, entertainment, and sports analytics. By leveraging deep learning and AI-powered techniques, computers can now interpret human actions in videos with remarkable accuracy.
This blog will explore how action recognition works, key techniques, real-world applications, and future trends. If you’re looking to understand how AI-powered video analysis is revolutionizing industries, this post is for you.
What is Action Recognition in Videos?
Action Recognition in Videos is a branch of Computer Vision that focuses on detecting and classifying human actions in video sequences. It involves identifying movements like walking, running, jumping, or even complex activities like dancing or playing sports.
Action recognition is crucial for automated surveillance, sports analytics, video indexing, and human-computer interaction. With the rise of deep learning, models can now analyze videos with precision, making real-time action detection a reality.
How Does Action Recognition Work?
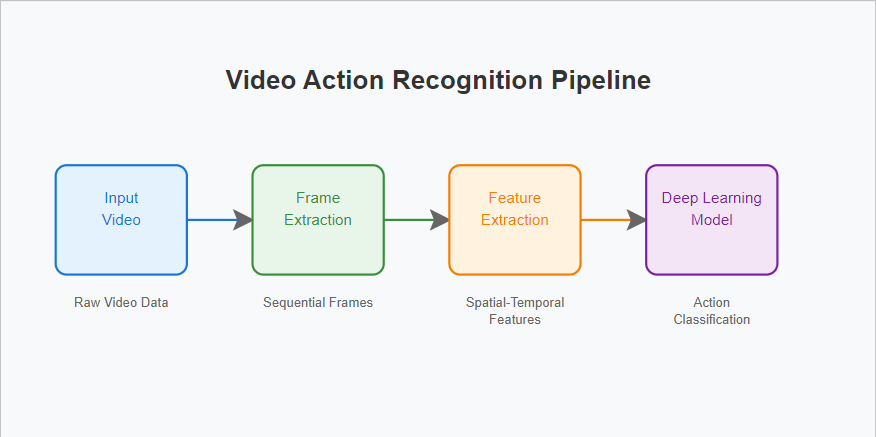
Action recognition involves several computer vision and deep learning techniques. The process generally follows these steps:
Frame Extraction: Videos are broken down into frames or sequences of images.
Feature Extraction: Extracting key visual elements like body movement, object interaction, and motion trajectories.
Temporal Analysis: Tracking movements across frames using Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, or Temporal Convolutional Networks (TCNs).
Classification: Using deep learning models like Convolutional Neural Networks (CNNs) and Transformers to classify actions based on learned features.
Modern approaches often use 3D CNNs, Two-Stream Networks, and Spatio-Temporal Graph Convolutional Networks (ST-GCNs) to enhance accuracy.
Key Techniques in Video Action Recognition
1. Convolutional Neural Networks (CNNs) for Feature Extraction
CNNs are widely used for image classification, but for videos, 3D CNNs are used to capture spatial and temporal features simultaneously.
2. Recurrent Neural Networks (RNNs) & LSTMs for Temporal Tracking
RNNs and LSTMs help capture motion patterns over time, allowing models to understand complex sequences like sports actions or gestures.
3. Two-Stream Networks
This approach processes both spatial (RGB frames) and temporal (optical flow) information, improving recognition accuracy.
4. Transformers & Attention Mechanisms
With the success of Vision Transformers (ViTs), attention-based models like TimeSformer and Video Swin Transformers have improved action recognition by efficiently handling long video sequences.
5. Graph Convolutional Networks (GCNs) for Skeleton-Based Recognition
For applications like human pose estimation, GCNs process skeletal data to recognize human actions with minimal noise.
The Technical Foundation: How Does It Work?
1. Feature Extraction
At its core, action recognition begins with extracting meaningful features from video frames. Modern approaches use:
Spatial features: Understanding what’s in each frame
Temporal features: Analyzing how movement occurs across frames
Spatio-temporal features: Combining both to understand actions in context
2. Deep Learning Architectures
The field has evolved significantly with deep learning, particularly through:
3D Convolutional Neural Networks (3D CNNs):
Process video data directly
Learn hierarchical representations of motion
Capture both spatial and temporal information simultaneously
Two-Stream Networks:
RGB stream for spatial information
Optical flow stream for motion information
Fusion of both streams for comprehensive understanding
3. State-of-the-Art Approaches
Recent advancements have introduced sophisticated architectures:
Monitoring patient movements for recovery analysis
Fall detection in elderly care facilities
3. Sports Analytics
Tracking player movements in football, basketball, and cricket
Enhancing training by analyzing player techniques
4. Smart Retail & Customer Insights
Understanding customer behavior in stores
Optimizing store layouts based on movement patterns
5. Autonomous Vehicles
Pedestrian action recognition for safer self-driving cars
Predicting road user behavior
6. Entertainment & Media
Action-based video recommendations (e.g., Netflix, YouTube)
Enhancing motion capture in gaming and movies
Challenges in Action Recognition
Despite advancements, action recognition faces several challenges:
Occlusions & Background Clutter: Objects or other people in the frame can obscure actions.
Variability in Actions: The same action can have different styles (e.g., different running postures).
Computational Cost: Training deep learning models on large video datasets is resource-intensive.
Real-Time Processing: Achieving low-latency action recognition in live videos remains a challenge.
Future Trends in Video Action Recognition
1. Real-Time Edge Computing
Processing action recognition on-device (e.g., mobile phones, surveillance cameras) rather than relying on cloud computing.
2. Multimodal Learning
Combining visual data with audio to improve recognition accuracy (e.g., understanding conversations in videos).
3. Self-Supervised Learning
Reducing dependence on labeled data by allowing models to learn from unlabeled videos.
4. AI-Generated Training Data
Using synthetic datasets to train models faster and more efficiently.
Conclusion
Action Recognition in Videos with Computer Vision is revolutionizing industries by enabling real-time human activity analysis. From security and healthcare to sports analytics and retail, its applications are endless. With advancements in deep learning, transformers, and multimodal AI, we are moving towards a future where AI can understand human actions with near-human accuracy.
If you’re a data scientist, AI researcher, or business leader, now is the perfect time to explore video action recognition and its potential impact.