
Introduction
Have you ever wondered why so many machine learning projects fail to reach production? In fact, nearly 87% of data science projects never make it past the experimental phase. This alarming statistic highlights a critical gap between developing models and successfully deploying them. However, there’s good news! By implementing robust MLOps practices, you can dramatically increase your success rate.
Moreover, effective MLOps implementation doesn’t just help models reach production—it transforms how organizations deliver AI value. Throughout my 11 years in the field, I’ve seen firsthand how proper MLOps practices can reduce deployment time from months to days while significantly improving model reliability.
In this comprehensive guide, I’ll share battle-tested MLOps best practices that will revolutionize your model deployment pipeline. Furthermore, these practices will help you overcome common challenges and establish continuous, reliable deployment workflows that scale.
Understanding MLOps: Beyond the Buzzword
MLOps isn’t just another tech buzzword to ignore. Instead, it represents the intersection of machine learning, DevOps, and data engineering—a critical discipline for organizations serious about AI implementation.
At its core, MLOps focuses on standardizing and streamlining the machine learning lifecycle. Additionally, it bridges the gap between development and operations teams, creating a unified workflow from experimentation to production.
To clarify what makes MLOps different from traditional software deployment, consider these key distinctions:
| Traditional DevOps | MLOps |
| Code-centric | Data and model-centric |
| Binary versioning | Data, model, and code versioning |
| Unit tests for validation | Performance metrics validation |
| Single pipeline deployment | Training and inference pipelines |
herefore, MLOps requires specialized practices tailored to the unique challenges of ML systems. Above all, it demands a mindset shift from one-off model creation to sustainable, reproducible AI delivery.
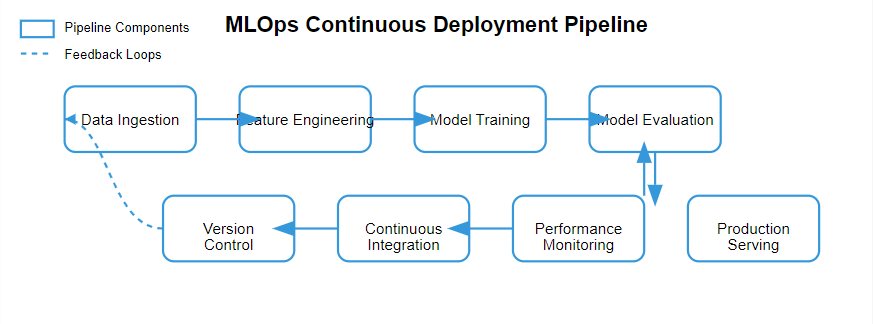
7 Game-Changing MLOps Best Practices
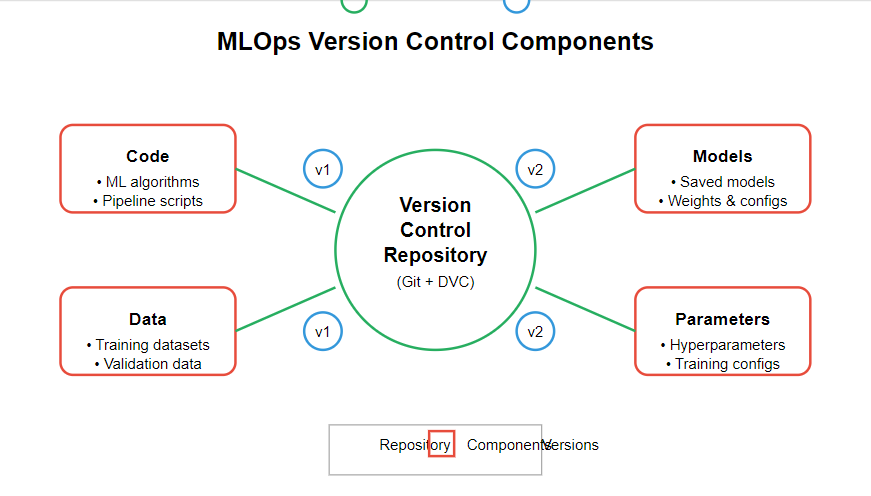
1. Implement Rigorous Version Control
Successful ML projects require meticulous tracking of multiple components. First and foremost, you need comprehensive version control that covers:
- Model code and parameters
- Training and validation datasets
- Feature engineering pipelines
- Configuration files and hyperparameters
- Runtime environments
For example, tools like DVC (Data Version Control) work alongside Git to manage datasets and model artifacts. Meanwhile, platforms like MLflow provide experiment tracking capabilities that capture metrics and parameters.
# Example: Using MLflow for experiment tracking and model versioning
import mlflow
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Set experiment name
mlflow.set_experiment("fraud_detection_model")
# Start tracking run
with mlflow.start_run(run_name="random_forest_classifier"):
# Log parameters
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 10)
# Train model
model = RandomForestClassifier(n_estimators=100, max_depth=10)
model.fit(X_train, y_train)
# Log model
mlflow.sklearn.log_model(model, "model")
# Log metrics
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
mlflow.log_metric("accuracy", accuracy)Subsequently, this approach ensures reproducibility and enables easy rollbacks when needed. As a result, teams can confidently iterate while maintaining a clear history of all changes.
2. Establish Automated Testing Pipelines
ML systems require a broader testing approach than traditional software. Consequently, your testing strategy should include:
- Data validation tests: Verify data schema, distributions, and quality
- Model performance tests: Ensure model metrics meet defined thresholds
- Integration tests: Validate model behavior within the larger system
- A/B testing: Compare new models against existing ones
Furthermore, automated CI/CD pipelines should trigger these tests at appropriate stages. Hence, tools like GitHub Actions or Jenkins can orchestrate test execution.
python
# Example: Data validation with Great Expectations
import great_expectations as ge
# Load your batch of data
batch = ge.read_csv("new_training_data.csv")
# Create an expectation suite
batch.expect_column_values_to_not_be_null("important_feature")
batch.expect_column_values_to_be_between("target_variable", min_value=0, max_value=1)
batch.expect_column_mean_to_be_between("numerical_feature", min_value=0.5, max_value=1.5)
# Validate expectations
results = batch.validate()
# Fail the pipeline if validation fails
assert results["success"], "Data validation failed. Pipeline halted."After implementing these testing pipelines, you’ll catch issues earlier, resulting in more reliable deployments. Thus, this practice builds confidence in your model releases and prevents problematic models from reaching production.
3. Build Modular, Reproducible Pipelines
Effective MLOps requires breaking the ML workflow into discrete, reusable components. Therefore, create modular pipelines that separate:
- Data ingestion and preprocessing
- Feature engineering
- Model training and evaluation
- Model serving and monitoring
Meanwhile, tools like Kubeflow Pipelines, Airflow, or Prefect can orchestrate these components. Additionally, containerization with Docker ensures consistent environments across stages.
# Example: Defining a modular ML pipeline with Kubeflow
from kfp import dsl
@dsl.pipeline(
name="Fraud Detection Training Pipeline",
description="End-to-end training pipeline for fraud detection model"
)
def fraud_detection_pipeline(data_path, model_name, training_params):
# Data preprocessing component
preprocess_op = preprocess_component(data_path=data_path)
# Feature engineering component
features_op = feature_engineering_component(
data=preprocess_op.outputs['processed_data']
)
# Model training component
train_op = train_component(
features=features_op.outputs['features'],
labels=features_op.outputs['labels'],
hyperparameters=training_params
)
# Model evaluation component
eval_op = evaluate_component(
model=train_op.outputs['model'],
test_features=features_op.outputs['test_features'],
test_labels=features_op.outputs['test_labels']
)
# Model registration component - only if evaluation passes
with dsl.Condition(eval_op.outputs['metrics_passed'] == 'True'):
register_op = register_model_component(
model=train_op.outputs['model'],
metrics=eval_op.outputs['metrics'],
model_name=model_name
)Consequently, this modular approach enables reuse, faster iterations, and easier troubleshooting. In addition, it supports parallel development and facilitates unit testing of individual components.
4. Implement Feature Stores for Production
Feature engineering represents one of the most time-consuming aspects of ML development. Accordingly, feature stores solve this challenge by providing:
- Centralized repository for production-ready features
- Consistent feature transformations across training and serving
- Feature versioning and lineage tracking
- Efficient serving for real-time and batch inference
Today, tools like Feast, Tecton, and Hopsworks offer feature store capabilities that integrate into MLOps workflows. Besides saving engineering time, these solutions ensure consistency between training and serving environments.
# Example: Using Feast feature store for training and inference
from feast import FeatureStore
import pandas as pd
# Initialize the feature store
store = FeatureStore(repo_path="./feature_repo")
# Retrieve features for training (historical data)
training_df = store.get_historical_features(
entity_df=pd.DataFrame({
"user_id": user_ids,
"event_timestamp": timestamps
}),
features=[
"user_features:age",
"user_features:average_spend",
"transaction_features:transaction_count_7d",
"transaction_features:average_transaction_amount_30d"
]
).to_df()
# Training process using these features
# ...
# Later - retrieve features for online inference
features = store.get_online_features(
entity_rows=[{"user_id": "user_123"}],
features=[
"user_features:age",
"user_features:average_spend",
"transaction_features:transaction_count_7d",
"transaction_features:average_transaction_amount_30d"
]
).to_dict()As a result of implementing feature stores, teams achieve faster development cycles and more consistent model performance. Above all, this practice addresses the critical challenge of feature consistency between training and serving.
5. Design for Scalable Model Serving
Production models must handle varying load demands and deliver consistent performance. In particular, your serving infrastructure should support:
- Horizontal scaling to handle traffic spikes
- Multiple deployment patterns (batch, real-time, streaming)
- A/B testing and shadow deployments
- Resource efficiency and cost optimization
Currently, technologies like TensorFlow Serving, TorchServe, or KServe provide specialized model serving capabilities. Meanwhile, containerized deployments with Kubernetes enable scalable orchestration.
For complex serving needs, consider these deployment patterns:
| Pattern | Use Case | Benefits |
| Model-as-Service | Real-time predictions with REST API | Simple integration, synchronous responses |
| Batch Inference | Regular predictions on large datasets | Resource efficiency, high throughput |
| Streaming Inference | Continuous predictions on data streams | Low latency, event-driven architecture |
| Edge Deployment | IoT and mobile applications | Reduced bandwidth, offline capabilities |
Therefore, investing in robust serving infrastructure ensures your models deliver business value reliably and efficiently. For instance, a well-designed serving layer can handle 10x traffic spikes while maintaining consistent latency.
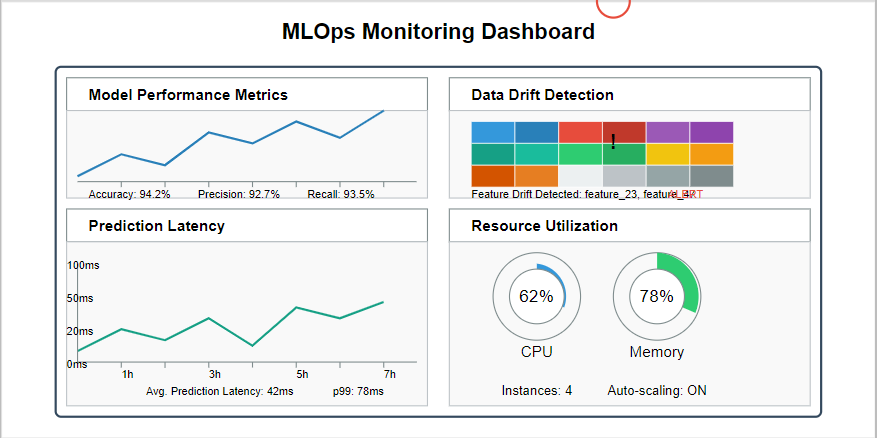
6. Establish Comprehensive Monitoring
Model deployment isn’t the end—it’s just the beginning. Hence, implement monitoring that covers:
- Performance metrics: Accuracy, precision, recall, or custom business metrics
- Technical metrics: Prediction latency, throughput, resource usage
- Data drift detection: Changes in feature distributions over time
- Concept drift detection: Shifts in the underlying patterns models should capture
- Operational alerts: Notifications for critical issues requiring intervention
Then, tools like Prometheus, Grafana, and specialized ML monitoring solutions can create dashboards for visibility. In addition, alerting systems ensure timely responses to potential issues.
# Example: Setting up data drift monitoring with Evidently AI
from evidently.dashboard import Dashboard
from evidently.dashboard.tabs import DataDriftTab
from evidently.pipeline.column_mapping import ColumnMapping
import pandas as pd
# Reference data (training data)
reference_data = pd.read_csv("training_data.csv")
# Current production data
current_data = get_recent_production_data() # Your function to get recent data
# Configure column mapping
column_mapping = ColumnMapping(
prediction="prediction",
numerical_features=["feature1", "feature2", "feature3"],
categorical_features=["category1", "category2"]
)
# Create a data drift dashboard
data_drift_dashboard = Dashboard(tabs=[DataDriftTab(verbose_level=1)])
data_drift_dashboard.calculate(reference_data, current_data, column_mapping=column_mapping)
# Save the dashboard
data_drift_dashboard.save("data_drift_report.html")
# Get drift metrics for automated decision making
drift_metrics = data_drift_dashboard.get_metrics()
# Automated actions based on drift detection
if drift_metrics["data_drift"]["data_drift_detected"]:
trigger_model_retraining()
send_alert_to_team("Data drift detected - model retraining initiated")Subsequently, this practice enables proactive management of model health rather than reactive firefighting. Most importantly, it builds trust in deployed models by ensuring they continue performing as expected.
7. Create Self-Healing ML Systems
The most advanced MLOps implementations incorporate automated remediation. Therefore, design systems that can:
- Automatically roll back to previous versions when issues are detected
- Trigger retraining pipelines when performance degrades
- Adjust serving parameters based on load patterns
- Route traffic dynamically between model versions
For example, canary deployments gradually shift traffic to new models while monitoring key metrics. If problems emerge, traffic automatically reverts to the previous stable version.
By implementing these self-healing mechanisms, you reduce operational overhead and minimize potential downtime. Ultimately, this creates a sustainable system that requires less manual intervention.
Implementing MLOps in Your Organization
Adopting MLOps isn’t just a technical challenge—it’s also organizational. Thus, consider these steps for successful implementation:
- Start small: Begin with a pilot project to demonstrate value
- Build cross-functional teams: Bring together data scientists, engineers, and operations staff
- Invest in training: Upskill team members on MLOps tools and practices
- Establish clear metrics: Define what success looks like for your ML systems
- Iterate and improve: Continuously refine your processes based on lessons learned
Often, the biggest obstacles are cultural rather than technical. Therefore, focus on building a culture that values reproducibility, automation, and operational excellence.
Conclusion
Implementing MLOps best practices represents a transformative journey for organizations serious about delivering ML-powered solutions. Throughout this article, we’ve explored seven critical practices that can revolutionize your model deployment pipeline.
To recap, effective MLOps implementation requires:
- Comprehensive version control
- Automated testing pipelines
- Modular, reproducible workflows
- Feature store implementation
- Scalable serving infrastructure
- Robust monitoring systems
- Self-healing capabilities
By adopting these practices, you’ll not only increase the success rate of your ML projects but also establish sustainable processes that scale with your organization’s needs. Furthermore, you’ll build confidence in your deployed models and accelerate the delivery of AI value to your business.
Now it’s your turn to implement these practices in your ML workflow. Start small, measure your progress, and continuously improve. Most importantly, remember that MLOps is a journey—not a destination.
What MLOps practice will you implement first? I’d love to hear about your experiences in the comments below!
References
- MLOps Principles
- 10 Essential MLOps Best Practices
- MLOps Best Practices – MLOps Gym: Crawl
- MLOps Checklist – 10 Best Practices for a Successful Model Deployment
- The Ultimate Guide to A/B Testing Deep Learning Models
- Mastering Linear Regression in Machine Learning: The Ultimate Guide