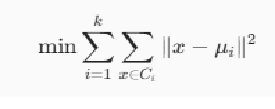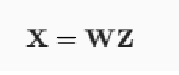import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_blobs
# Create our "candy bag" - a synthetic dataset
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# Clean and prepare our candies
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Sort the candies into groups
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X_scaled)
# Visualize our sorted candies
plt.figure(figsize=(10, 6))
scatter = plt.scatter(X_scaled[:, 0], X_scaled[:, 1],
c=kmeans.labels_, cmap='viridis')
plt.title('Sorting Our Data Candies')
plt.xlabel('Candy Property 1')
plt.ylabel('Candy Property 2')
plt.colorbar(scatter)
plt.show()